
Evasione, avvelenamento, privacy, abuso: ecco i possibili attacchi all’intelligenza artificiale secondo gli esperti del National Institute of Standards and Technology, agenzia governativa degli Stati Uniti che si occupa di tecnologie
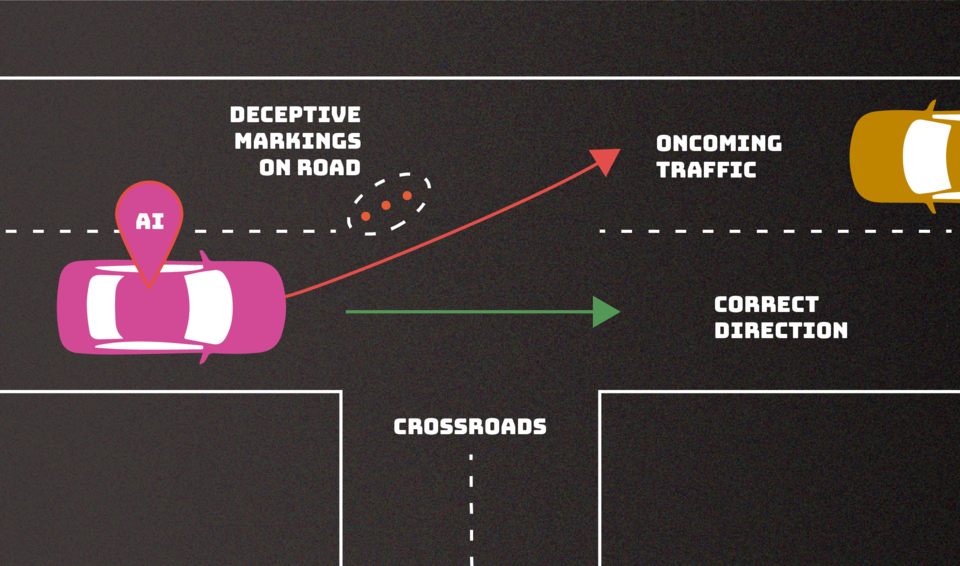
L’intelligenza artificiale che interviene e scambia un segnale di stop con un limite di velocità. O che dà indicazioni confuse. Che cosa potrebbe accadere? Rallentamenti nel migliore dei casi. Incidenti nel peggiore.
Questo scenario rientra in quelli possibili in caso di attacchi ai sistemi di intelligenza artificiale analizzati dagli esperti del National Institute of Standards and Technology, agenzia governativa degli Stati Uniti che si occupa di tecnologie. In particolare, si tratta di un attacco classificato come evasion (manipolazione), uno dei quattro studiati nel paper dal titolo “Adversarial Machine Learning: A Taxonomy and Terminology of Attacks and Mitigations”. “La pubblicazione, frutto della collaborazione tra governo, università e industria, ha lo scopo di aiutare gli sviluppatori e gli utenti dell’intelligenza artificiale a individuare i tipi di attacchi possibili e gli approcci per mitigarli, con la consapevolezza che non esiste alcuna soluzione definitiva”, si legge sul sito dell’agenzia. Si tratta di un’attività di red-teaming, quelle pensate per individuare e correggere le vulnerabilità dei modelli che hanno ormai permeato la società moderna (dai veicoli a guida autonoma alle chatbot di assistenza clienti fino al supporto ai medici nella diagnosi di malattie). Sono previste dall’executive order sull’intelligenza artificiale firmato dal presidente statunitense Joe Biden a fine ottobre (ma non dall’AI Act dell’Unione europea).
Oltre agli attacchi evasion gli studiosi hanno individuato quelli poisoning (avvelenamento), privacy e abuse (utilizzo malevolo). I primi si verificano nella fase di addestramento con l’introduzione di dati errati. Un esempio? Inserire parolacce nelle registrazioni delle conversazioni, in modo che una chatbot interpreti queste istanze come un linguaggio abbastanza comune da utilizzare nelle proprie interazioni con i clienti. I secondi si verificano durante l’implementazione come tentativi di apprendere, per fini impropri, informazioni sensibili sull’intelligenza artificiale o sui dati su cui è stata addestrata. Un avversario può porre a una chatbot numerose domande legittime e poi usare le risposte per fare reverse engineering del modello in modo da trovare i suoi punti deboli o indovinare le sue fonti. L’aggiunta di esempi indesiderati a queste fonti online potrebbe indurre l’intelligenza artificiale a comportarsi in modo inappropriato e farle disimparare quegli specifici esempi indesiderati dopo il fatto può essere difficile, spiegano gli esperti. I terzi prevedono l’inserimento di informazioni errate in una fonte, come una pagina web o un documento online, da cui l’intelligenza artificiale attinge. A differenza degli attacchi di avvelenamento, questi tentano di fornire all’intelligenza artificiale informazioni errate provenienti da una fonte legittima ma compromessa, al fine di riformulare l’uso previsto dal sistema di intelligenza artificiale.
“La maggior parte di questi attacchi sono abbastanza facili da realizzare e richiedono una conoscenza minima del sistema di intelligenza artificiale e capacità avversarie limitate”, ha dichiarato Alina Oprea, docente alla Northeastern University e co-autrice del documento. “Nonostante i notevoli progressi compiuti dall’intelligenza artificiale e dal machine learning, queste tecnologie sono vulnerabili agli attacchi che possono causare guasti spettacolari con conseguenze disastrose”, ha dichiarato Apostol Vassilev del Nist, un altro degli autori. “Ci sono problemi teorici di sicurezza degli algoritmi di intelligenza artificiale che semplicemente non sono ancora stati risolti. Se qualcuno dice il contrario, sta solo spacciando acqua di rose”, ha aggiunto.
(Foto: Nist)

