
Le Ai sono sempre più al centro del dibattito pubblico, in particolare, con riferimento a singoli aspetti legati a particolari sviluppi. Uno di questi è la capacità della macchina di riconoscere le persone mediante immagini (in inglese face recognition). Un sistema fino ad oggi utilizzato in ambito security ma che si appresta a rivoluzionare il mondo degli smartphone, i pagamenti digitali, i sistemi di accesso alle app e tanto altro, grazie all’integrazione di nuovi algoritmi di Intelligenza Artificiale e alla rapida evoluzione delle reti neurali.
Buona parte delle potenzialità dell’Ai oggi derivano dall’uso del deep learning che utilizza quantità di dati crescenti, ecco perché è importante fornire data set robusti e diversificati. In estrema sintesi: chi ha più dati ha più possibilità di allenare e rendere migliori gli algoritmi di machine learning.
La sfida nell’istruzione dei sistemi di Ai si manifesta in modo molto evidente e profondo nel caso della tecnologia di riconoscimento facciale, infatti, può essere molto difficile riuscire a creare sistemi di riconoscimento facciale in grado di soddisfare aspettative di equità.
LA NOVITÀ
Ibm Research ha annunciato nei giorni scorsi che rilascerà un nuovo set di dati, chiamato chiamato Diversity in Faces (DiF): un milione di immagini con annotazioni utili ad aiutare la comunità scientifica a rilevare, riconoscere e analizzare meglio le immagini dei volti.
Primo nel suo genere, questo importante programma scientifico consente di potenziare lo studio di precisione e l’accuratezza della tecnologia di riconoscimento facciale attraverso un insieme di annotazioni pari a circa 1 milione di immagini facciali umane. Affinché i sistemi di riconoscimento facciale basati sull’Ai funzionino correttamente nella novità di Ibm, i dati della formazione devono essere diversificati e devono potere offrire un’ampia copertura: infatti, i sistemi di intelligenza artificiale imparano ciò che gli viene insegnato.
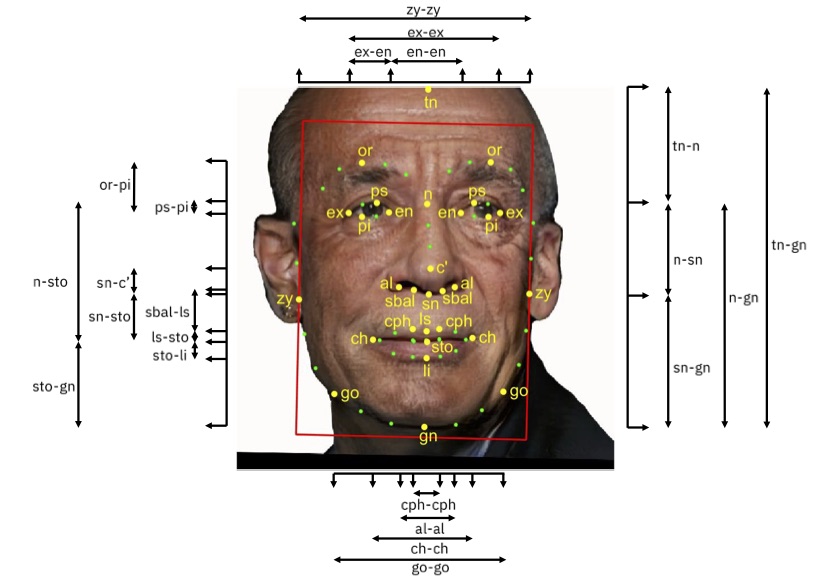
Le immagini devono riflettere la distribuzione delle caratteristiche facciali che vediamo nel mondo, in modo tale da permettere alla tecnologia di apprendere come i volti si diversificano per riconoscere attentamente tali differenze nelle più svariate situazioni. La maggior parte dei sistemi di riconoscimento facciale, infatti, funzionano con codici numerici chiamati “faceprints” (o “punti nodali”). I sistemi di riconoscimento facciale basati sulle “impronte facciali” possono identificare rapidamente e con precisione gli individui “obiettivo” quando le condizioni sono favorevoli. Tuttavia, se il volto del soggetto è parzialmente oscurato il software è meno affidabile.
COME FUNZIONA DIVERSITY IN FACES (DIF)
Il data set messo insieme da Ibm (DiF), attraverso l’utilizzo di immagini disponibili a livello pubblico dal data set Yfcc-100M Creative Commons, ha potuto catalogare i volti grazie a dieci schemi di codifica ben consolidati e indipendenti ricavati dalla letteratura scientifica [1-10]. Gli schemi di codifica includono principalmente misure oggettive dei volti umani, come ad es. lunghezza della testa, del naso, altezza della fronte, ma anche annotazioni soggettive come previsioni relative all’età e al genere tipiche dell’uomo. “Riteniamo che questo schema di codifica potrà accelerare lo studio della diversità per i sistemi di riconoscimento facciale basati sull’intelligenza artificiale e garantire maggiore precisione e accuratezza” ha dichiarato John R. Smith, manager Ai Tech dell’Ibm T. J. Watson Research Center, nel suo intervento sul blog che annuncia il primo rilascio DiF.
IN CHE MODO GARANTISCE LA DIVERSITÀ DEI VOLTI UMANI
Gran parte dell’attenzione rivolta alla tecnologia del riconoscimento facciale ha riguardato il livello di performance raggiunto usando attributi quali età, genere e colore della pelle, constatando come i diversi volti possono differire nell’ambito di alcuni di questi parametri. Tuttavia, come emerge da precedenti studi, questi attributi rappresentano solamente un tassello del puzzle e non sono in grado di caratterizzare interamente l’ampia diversità dei volti umani. Sono importanti anche dimensioni come la simmetria e il contrasto facciale (luminosità), la posa assunta dal volto, la lunghezza o larghezza delle varie parti del viso (occhi, naso, fronte, ecc.).
“Le nostre prime analisi mostrano che il data set Dif fornisce una distribuzione più bilanciata e una copertura più vasta di immagini facciali rispetto ai precedenti data set. Inoltre, le informazioni ottenute dall’analisi statistica dei 10 schemi di codifica iniziali di DiF hanno approfondito la comprensione di ciò che è importante per la caratterizzazione dei volti umani” aggiunge Smith sottolineando l’importanza della condivisione con tutta la comunità mondiale di ricercatori per compiere ulteriori passi avanti nella creazione di sistemi Ai più equi. Il data set Dif è infatti a disposizione della comunità scientifica dietro richiesta.
La notizia relativa a Ibm acquista ancora maggiore rilevanza, se teniamo presente la spinta cinese all’uso dell’intelligenza artificiale e alle tecnologie in grado di rendere semplicissimo il riconoscimento facciale: ad esempio la Cina utilizza già 176 milioni di telecamere di sorveglianza e si prevede ne aggiungerà altre 450 milioni entro il 2020 (qui l’approfondimento di Paolo Benanti).

