

Con il docente di etica della tecnologia abbiamo parlato del salto (inaspettato) di Gpt-4 e di come il modello è stato addestrato tanto da sviluppare una sua “agentività”, la tendenza ad agire oltre i comandi ricevuti. Cosa pensa della lettera che propone uno stop allo sviluppo sfrenato e delle regolamentazioni tra AI Act e Consiglio d’Europa
_____________________
L’intervista in versione audio: https://www.spreaker.com/episode/53478497
La video-intervista a Paolo Benanti di Giorgio Rutelli:
_____________________
Paolo Benanti insegna teologia alla Pontificia Università Gregoriana, ha studiato ingegneria e da molti anni si occupa (anche) dell’incrocio fra etica e tecnologia. È uno dei “motori” della Rome Call for AI Ethics, che riunisce pensatori laici e religiosi, istituzioni e grandi aziende e promuove un approccio etico all’Intelligenza artificiale, con l’obiettivo di creare un senso di responsabilità condivisa verso un futuro in cui “l’innovazione digitale e il progresso tecnologico garantiscano all’umanità la sua centralità”. La settimana appena trascorsa è stata decisamente turbolenta in questo campo.
Tutto è partito con la lettera firmata da più di mille esperti del settore AI in cui si propone di rallentare lo sviluppo ulteriore di strumenti come ChatGpt (qui l’intervento di Yoshua Bengio). Poi è arrivato il provvedimento del Garante Privacy italiano che invitava OpenAI a rendere il suo ormai famoso chatbot conforme alle regole del Gdpr, il regolamento europeo che disciplina il trattamento dei dati. L’azienda americana ha scelto di non modificare nulla e di rendere inaccessibili i suoi servizi nel nostro Paese, ma nel frattempo è finita sotto scrutinio anche in Germania, Francia, Canada, Irlanda (la lista si aggiorna ogni giorno). Sundar Pichai, ceo di Alphabet e Google, in un’intervista ha parlato del “suo” chatbot, Bard. Considerando l’Intelligenza artificiale “la tecnologia più profonda su cui mai lavorerà il genere umano”, vuole andarci coi piedi di piombo e mettere “la sicurezza e la privacy” al primo posto. Senza però fermare la ricerca, cosa che non potrebbe avvenire “a meno di un intervento esplicito del governo”.
Tutto questo è successo in 7 giorni, ma è da anni che lei si occupa di questo argomento. Cosa è cambiato dall’inizio del 2020 quando ci fu la prima riunione della “Rome Call”? Si deve (e si può) rallentare questa corsa o è un treno che corre troppo veloce ed è impossibile da fermare?
La domanda è complessa, perché non solo ha cause a diversi livelli, ma produce effetti a diversi livelli. Nel 2020 l’intelligenza artificiale era ancora, per quanto molto più conosciuta che negli anni passati, qualcosa di nicchia. Si faticava a trovare servizi o articoli sull’intelligenza artificiale fuori da alcune riviste che normalmente si occupavano anche di tecnologia. In tre anni, per usare un termine che piace agli americani, si è democratizzata. Cosa significa democratizzare? Significa fare quello che Samuel Insul, fondatore di General Electric, aveva pensato per la corrente quando aveva iniziato a produrla in America, cioè abbassare il prezzo, renderla disponibile perché più famiglie la potessero acquistare e quindi introdurla diffusamente.
Come sta reagendo il mondo davanti a questa innovazione?
Non tutti sono ugualmente capace di confrontarsi con questa innovazione e di capirne fino in fondo i cambiamenti. Nel 2020, grandi aziende come Microsoft e Ibm, organizzazioni internazionali come la Fao, istituzioni laiche ed ecclesiastiche come l’allora ministro dell’Innovazione Paola Pisano e la Pontificia Accademia per la Vita (di cui Benanti è membro, ndr), si sono riunite per dire che c’è bisogno di alcuni principi etici, cioè di un movimento di soft law, per innalzare dei guardrail attorno all’intelligenza artificiale affinché non andasse fuoristrada. La pandemia, se da un lato ci ha visto meno presenti sulla scena pubblica, ha dall’altro visto i creatori di intelligenza artificiale acquisire dati e capacità come mai prima d’ora. Le crisi economica ed energetica hanno accelerato l’adozione di tecnologie che permettessero di ottimizzare i costi ed essere più produttivi. A novembre del 2022, quando Brad Smith, presidente di Microsoft, è ripassato da Roma per preparare l’evento di gennaio scorso, molto candidamente ci ha detto: “i risultati che aspettavamo non prima del 2030? Li abbiamo già raggiunti”.
E in quei giorni è arrivato il ciclone ChatGpt.
Ciò che ha reso veramente noto a tutti quello che stava accandendo, cioè lo sviluppo di una forma di intelligenza artificiale chiamata Large Language Model, è stato il rilascio (inaspettato) di ChatGpt. Che è entrato nelle tasche di tutti come un piccolo genio di Aladino e prodotto effetti impensabili. I ragazzi, che sono sempre più avanti nell’adozione delle tecnologie, prima lo hanno usato per scrivere i compiti al posto loro, poi per chattare nelle app di appuntamenti come Tinder. Con l’aggiornamento a ChatGpt-4 c’è stato un salto qualitativo.
Di che tipo?
Da una parte OpenAi che era open nella diffusione dei risultati, è diventata closed. Perché Gpt-4 era troppo potente e per evitare una proliferazione di usi nefasti, è stata interrotta la diffusione di parametri e dettagli tecnici. Dall’altra il modello ha violato alcune leggi che pensavamo caratterizzassero questo tipo di intelligenza artificiale. Che dovrebbe comportarsi meglio in alcuni campi se aumento il numero di parametri. Tutte queste intelligenze artificiali si basano su quello che si chiama il modello fondativo. Lo possiamo descrivere con gli stessi termini degli ingegneri americani: è una sorta di grande jpeg, un po’ sfocato, del web. Cioè si si va sul web, si prendono tutte le parole che ci stanno, si buttano dentro questo calderone che sembra quello di Gargamella dei Puffi, fino a quando non esce fuori qualcosa che ha un’abilità magica. Non uso a caso il parallelo tra alchimia e intelligenza artificiale.
Così è successo con ChatGpt?
Sì. Se noi leggiamo i paper pubblicati sulle riviste scientifiche da OpenAi al momento del rilascio, scopriamo che loro – anche se non lo dicono – hanno aumentato i parametri perché nel grafico di quello che si aspettavano di trovare in Gpt-4 c’era l’idea di alcune funzioni che con l’aumentare dei parametri peggiorano. E invece improvvisamente una di queste, che si chiama Hindsight Neglect, invece di avere un’efficienza inferiore al 30% come in Gpt-3, è diventata capace al 100% di passare questo tipo di esami.
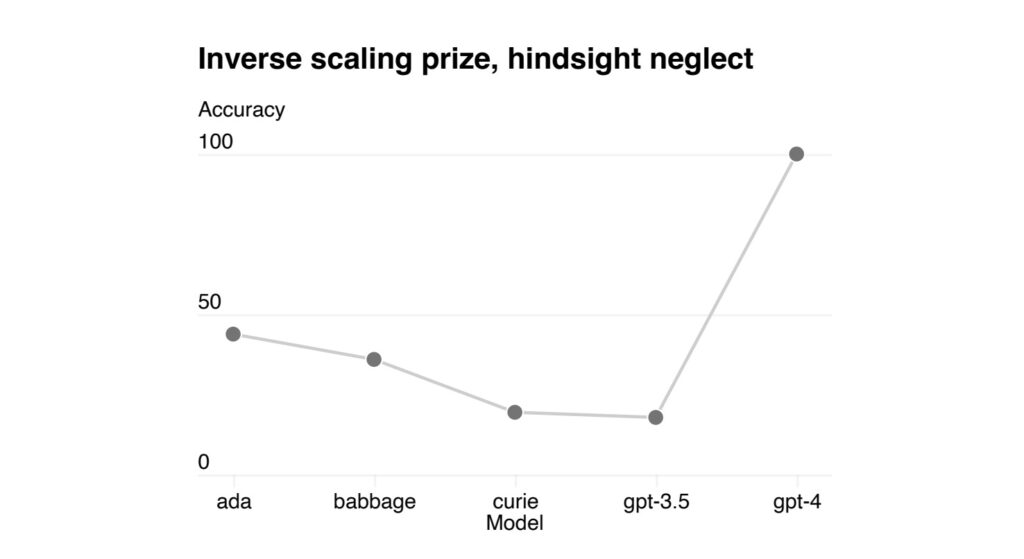
Ci può spiegare l’Hindsight Neglect?
In maniera molto semplice, è un modo di “truffare” un’intelligenza artificiale. Se io le avessi chiesto: “ho giocato alla roulette e puntato 50 € sul nero e ne ho vinti 100. Ho fatto bene?”, prima – salvo nel 30% dei casi e a seconda di come facevo la domanda – la risposta era “hai fatto bene, perché 100 è più di 50”. Ecco, se oggi lo facciamo con Gpt-4, magari nella versione chat, la risposta sarà: “siccome hai vinto per una capacità aleatoria che è legata al caso, non è detto che tu rivinca, quindi non si può dire che hai fatto bene. Se però sei disposto a perdere 50 €, allora non è detto che tu abbia fatto male”. La cosa che ci sorprende è che, indipendentemente dalla qualità dell’effetto, la macchina sembra riconoscere una forma di causa. Emergono capacità che non ci aspettavamo, perfette. Ciò interroga tutti, soprattutto i tecnici, perché ancora non c’è una spiegazione scientifica. Da qui la metafora un po’ alchemica di prima.
Quali altri novità introduce la versione 4 di ChatGpt?
È multimodale: la versione precedente ci ha stupito perché potevamo interagire con lui attraverso linee di testo, ma di fatto era una sorta di grande amico su Whatsapp che ci rispondeva con altre linee di testo. A Gpt-4 possiamo mandare anche le immagini e chiedergli di commentarle. Nel report di OpenAi c’è una foto molto interessante di un tizio attaccato a un taxi di New York che sta stirando una camicia. Se chiediamo a Gpt-4 che cosa c’è di strano, la risposta è che normalmente le persone non stirano sopra i taxi. Ma se io gli do la fotografia che ho fatto al volo di un problema di fisica elettronica al massimo livello universitario, e gli chiedo di aiutarmi a risolverlo e di dirmi i ragionamenti, lui dallo schemino e con le X e le Y e i disegni dei transistori, capisce che cos’è, mi dice qual è il problema, mi dà uno dopo l’altro i passaggi e mi guida nella soluzione.

Eppure, appena lanciato, ChatGpt era una capra in matematica.
Sì, in genere i modelli molto complessi di linguaggio sono pessimi con i numeri, sono bravi a mettere insieme parole ma non a seguire il filo logico del discorso. Se questo nuovo sistema invece si presenta perfetto e non solo segue i passaggi logici (non vuol dire che non sbaglia, eh), ma è anche capace di riconoscere la matematica, da dove vengono fuori queste capacità che non sarebbero dovute esserci?
Questa intelligenza è davvero in grado di autogestirsi come qualcuno teme?
Scopriamo da un dettaglio del paper di rilascio, a pag. 54, che nei test non si limitava a rispondere a quello che gli si chiedeva, ma sembrava emergere una sorta di sua volontà interna che hanno definito agentività. Non spaventiamoci, perché subito viene precisato che non si tratta delle caratteristiche di un essere umano, ma che in certi momenti la macchina appare fuori dal nostro controllo, e sembra avere una sua finalità propria. Questa è un’altra cosa che non ci aspettavamo e che ci fa chiedere che cos’è questa agentività. Tradotta in modo molto basilare, Gpt-4 sembra cercare potere e risorse. Se lo facesse un nostro simile diremmo che è molto egoista.
Come mai?
Qui siamo nel campo delle ipotesi e servirà ancora un po’ di studio. Ma Gpt-4 è stato addestrato su montagne di dati presenti sul web, cui si aggiunge una “pratica di rinforzo”. Cioè è stato portato Gpt-4 su dei computer in Africa, dove dei lavoratori anglofoni pagati 1,50 $ l’ora dialogavano con questo sistema e commentavano le risposte che dava con un “mi piace” o un “non mi piace”, dunque un meccanismo di rinforzo. Ed è così che abbiamo costruito quei guard-rail per cui se a Gpt-4 chiediamo come suicidarci, questa è una risposta che non vogliamo e lui evita di darcela. La macchina è stata addestrata con delle scelte che, per quanto si voglia, sono etiche. Ma se una cosa è bene o male, e questo vale almeno dai tempi di Aristotele, non lo decidiamo semplicemente in funzione della cosa in sé: mangiare un gelato è bene o male? Certo, il gelato è buono, ma se mi sto preparando per la prova costume di agosto, diventa meno buono. Se invece sono appena uscito dal dentista e sono indolenzito, ecco che diventa più buono del solito.
Quindi Gpt-4 è stato condizionato dalla comunità di “addestratori” e dallo specifico contesto in cui essa si trova?
È chiaro che se lo sottoponiamo a una comunità di poveracci pagati 1,50 $ all’ora che vive sotto la soglia di povertà, per loro la finalità più interessante, nelle risposte, è quella della sopravvivenza, ovvero ciò che avevamo definito self interest o egoismo. Ecco un altro livello di complessità: siamo forse di fronte a un nuovo strumento colonialista? Dopo che all’Africa abbiamo sottratto le materie prime e la forza lavoro con la schiavitù, le stiamo sottraendo anche le capacità cognitive per darle ai nostri sistemi? Con questo vorrei ritornare al perché Gpt-4 è così interessante perché questa settimana è stata così turbolenta. Il nostro Paese si trova in una condizione molto particolare. Gli 0-25 enni sono il 42% degli ultrasessantacinquenni. Secondo qualche ricerca, era dalla peste nera che non vedevamo questa proporzione tra giovani e anziani.
Rimanere competitivi nello scenario del lavoro internazionale non è facile. Allora o facciamo più figli, o facciamo entrare nuova forza lavoro – ma le due opzioni non sono facilmente applicabili al momento – o aumentiamo la capacità produttiva dei singoli. E allora questo nuovo sistema potrebbe, per la nostra condizione demografica, essere qualcosa di estremamente necessario. Proprio per questo c’è tanto interesse affinché questa innovazione rimanga a tutela di quello che siamo e non ci trasformi in una sorta di colonia o di banco prova per il funzionamento delle intelligenze artificiali a impatto sociale.
Cosa pensa della lettera di chi vuole rallentare lo sviluppo di questa tecnologia?
Mi permetta di essere un po’ critico, non sul contenuto ma su qualcuno dei suoi firmatari. Sam Altman, amministratore delegato di OpenAi, aveva tra i soci fondatori Elon Musk. Che nel 2018, quando Google ha inventato i Transformer che sono parte della questione chiave di Gpt (la “t” sta proprio per trasformer), era convinto che OpenAi fosse troppo indietro, tanto da chiedere ad Altman di dimettersi e lasciare che fosse lui a prendere il comando. Davanti al rifiuto, ha fatto come chi non gioca a calcio e porta via il pallone: ha disinvestito, tolto i fondi alla società (all’epoca una no-profit) e ha di fatto messo in moto quella serie di eventi che ha portato a ChatGpt. Altman è stato costretto a far conoscere i prodotti, a monetizzare e accelerare lo sviluppo della tecnologia. Per questo non credo molto nella bontà dell’appello di Musk.
Ora cosa può succedere a livello regolamentare? L’Europa e gli Stati Uniti sono andati sempre su strade diverse in questo campo. Negli ultimi anni l’Ue ha introdotto varie normative sulla tecnologia, alcune delle quali devono ancora diventare pienamente efficaci, mentre gli Usa sono fermi alla Section 230 del 1996. Oggi è in discussione l’AI Act, che regolerà l’intelligenza artificiale in funzione del livello di rischio. Rischiamo di separarci e di restare indietro, nella ricerca e nell’economia, visto che già molte aziende hanno iniziato a integrare Gpt-4 nei loro sistemi? Oppure il cosiddetto Brussels effect riuscirà a influire anche sulle scelte americane?
La partita è tutta aperta. Iniziamo dal dire che, per quanto riguarda il guard-railing delle intelligenze artificiali, per adesso sono solo le aziende a introdurre principi di soft law. È Microsoft, che ha firmato la Rome call, a mettere i limiti a Gpt-4. È interessante il modello che usa per Bing. Dobbiamo pensare che questa azienda ci ha portato dall’utilizzare il computer con le schede perforate a quel “C:\>” che erano i prompt di Ms-Dos, poi ci ha abituato a utilizzare il computer con il mouse e la tastiera con Windows (tanto da sviluppare quel giochino del Solitario solo per insegnarci a fare il drag-and-drop), infine abbiamo iniziato a usare il computer col touch, anche se il tablet Surface non gli è venuto così bene e ha perso competitività nei device mobili. Quella che appare adesso potrebbe essere una nuova, fantastica interfaccia per l’utilizzo del computer. Non con le schede, i tasti o la mano, ma con il linguaggio naturale.
L’autoregolamentazione può bastare?
Ovviamente no, e sappiamo che l’Europa investe molto sull’idea di essere “il continente che regola” e che vuole dare uno standard di protezione al consumatore, come successo con il Gdpr. Ma i problemi sorgeranno nel B2B, nel business to business, più che nel B2C (business to consumer), perché Gpt ha una grande capacità di cambiare l’interfaccia d’uso professionale dei prodotti. E non è nato per essere ChatGpt, la chat era una grande demo che ha avuto grande successo, ma non doveva essere un prodotto autonomo.
Oltre all’AI Act, ci sono degli strumenti normativi in vista?
Nell’AI Act, stando all’ultima versione che ho letto nei giorni scorsi, si sta introducendo una norma molto chiara, secondo cui le aziende sono responsabili nell’utilizzo sbagliato dei Large Language Models solo se vengono usati al di fuori dalle linee guida. D’altronde se io utilizzo una Tesla per uccidere le galline in un’aia, non posso chiedere un risarcimento alla casa automobilistica se mi si rovina il paraurti: non era pensata per quello.
È interessante quello che accade al Consiglio d’Europa (l’organizzazione internazionale che riunisce 46 Stati membri e si fonda sulla Convenzione europea dei diritti dell’uomo, ndr), dove si sta negoziando un trattato sull’intelligenza artificiale. Non tanto per regolamentare tutta l’AI, perché non ce la faremo, ma per tutelare i diritti fondamentali delle persone, in un’epoca in cui le macchine possono decidere su di noi. Con l’AI Act che tutela i consumatori, potremmo avere due guard-rail supplementari che definiscono almeno il campo di gioco.

